库(Library)在wikipeida的定义如下:
In computer science, a library is a collection of resources used to develop software. These may include pre-written code and subroutines, classes, values or type specifications.
在我们写程序的过程中几乎每时每刻使用着库。我们在编码的过程中享受着库带给我们的便利和好处。现在的编程语言都会提供丰富的库给开发者调用,比如C++的库有STL、Boost, Java的库有Swing。像PHP,Python等更是提供了强大的库来帮助程序员开发网站(当然这些语言不仅能用来开发网站),这些库针对网站开发中遇到的常见问题提供了解决方案。举个例子来说,假设我们要将一个PHP数组用json的格式传到客户端,在没有库的情况下我们可能要遍历整个数组然后按照json的格式构建一个string,这样至少需要四五行代码,可是现在一个json_enode就可以搞定了。并且无论数组是几维的,json_encode都能正确返回json格式的string。
- 代码复用
- 保证质量
- 提高效率
代码复用
从软件工程的角度看,代码复用可以节约成本,提高开发效率,使代码易维护(只需维护一处地方即可),除此之外代码复用也能提高整体软件的质量。当我们使用库的时候,自己写的代码量减少,这样出错的几率就相应的降低了,同时开发的速度也提高了。以前可能要花几分钟写的一段代码,现在只要一个调用就搞定了。从管理者的角度看软件的最大成本“人/月”得到了降低。
保证质量
这里的质量指的是库的质量。一般而言,官方提供的库的质量都是相当高的。这些代码都经过大量的测试和用户使用的考验。一旦有什么bug很容易发现,并且及时改正过来。同时编写这些库的人都是领域中的大牛,他们有着许多年的开发经验,写的代码照理说肯定比我们自己写的要质量高。在Effective C++中有这么一个Item: “Familiarize yourself with Boost",在这个Item里面Meyers介绍了一个库在被Boost接受前经历的步骤,包括公开的同级评审(peer review),评审经理的审查(review manager),社区的正式评审(official review)。整个过程被boost概述为“讨论、精炼、多次提交直到感到满意”的循环。有着这样严格的审查过程,Boost库的质量可想而知。
提高效率
这里的效率是指程序执行时的时间和空间效率。一般而言库中提供程序的效率总是高于我们所写的程序(当然在某种特定的应用场景下,我们写的代码效率可能会更好,毕竟库是个通用的东西,它不可能考虑某个特别的应用场景)。下面就举3个典型的例子来说明库的效率:
第一个例子是SGI STL的power算法,其代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
从上面的代码可以看到这是一个power的非递归实现。为了效率作者没有使用递归的实现,尽管递归版本看上去更直观。为了效率作者连除法运算符都不敢用,都是用了移位和OR这些bitwise operator,这些bitwise operator在计算机中是算得最快的。我想我们自己写的power实现应该不会比它快吧。
第二个例子是SGI STL的copy算法,其脉络如图(来自侯捷老师的《STL源码剖析》):
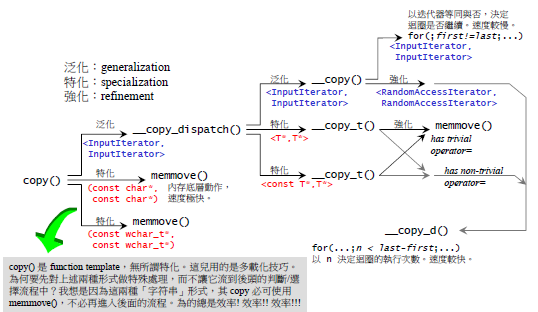
从上图可以看出,虽然copy算法给我们的是一个统一的接口,但其内部却是有多个实现方式,目的是针对不同的情况给出最佳的copy实现。为了利用memmove(),作者想尽了一切办法,又是泛化又是特化。同时作者对于for(;first!=last;…)和for(…; n < last-first; …)这样两种循环方式的效率差异性都进行了考虑。所有这一切的目的只有一个就是提高效率。用侯捷老师的话说就是强化效率无所不用其极
。关于更多SGI STL copy算法的实现,可以参考侯捷老师的《STL源码剖析》。
第三个例子是Java的数组拷贝算法: 为了高效的copy Java的数组,Java 类库专门提供了一个System.arraycopy的方法。那这个方法又有什么高级之处呢?通过查看源代码我们就可以发现这个方法是个native 方法。然后我们来看看OpenJDK是如何实现这个native方法的。经过一番查找可以找到以下代码代码片段:
1 2 3 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
我们又看到了memmove(),arraycopy的作者使用了JNI来调用了memmove(),为的就是效率。更恐怖的是这还有汇编指令,这些指令也能使数组拷贝变得十分高效。看到这,你觉得我们自己写的数组拷贝算法的效率能超过官方提供的吗? 详细的如何剖析arraycopy方法请参见勇点的博客。
看了这三个例子,我们应该能感受到库提供程序的效率了吧。即使我们能写出和库一样效率的算法,我们要花多少时间,写完的质量怎么样,这些都要打个问号。想想Java的System.arraycopy吧。
总的来说能使用库的时候尽量使用,这会使你的代码质量更高,效率更高。在软件工程中有句名言Don’t Reinvent the Wheel
,这就是我们对待库的态度。当然作为学生来讲,我们不仅要能熟练的使用库,最好还能深入库的源代码,像大师们取经,这会让我们受益匪浅。